I Somehow Built a RAG Chatbot with Fine-Grained Authorization—But Don’t Know How
I Somehow Built a RAG Chatbot with Fine-Grained Authorization—But Don’t Know How
Vibecoding an authorized RAG chatbot with minimal coding experience, facing a critical security incident, and learning how to debug something I don’t quite understand.
I have no software engineering background except for some hello-world-level Python knowledge, yet enough optimism (or rather foolishness) to encourage me to build a RAG chatbot with fine-grained authorization. As a performance marketer, it’s easy to fall into a routine of launching and managing campaigns, staring at performance metrics, or working on ad creative. One thing about marketers, however, is that we’re pretty good at breaking out of routines to keep our sanity and preserve our creativity.
This is probably why I decided to take on what seemed like an impossible project for me on a random Tuesday. To build a RAG chatbot, I recently learned that you need an LLM and a vector database. For the purposes of mimicking a real-world use case, I imagined that I was building a sales assistant bot—helping salespeople remember details about their potential clients. For instance, a salesperson could ask: “What did Mike from ACME Corp think about our pricing structure when we had a meeting last year?”
Technology & Tooling
I obviously tapped into the OpenAI API, which was a straightforward choice. For my database, I really wanted to use Supabase—but that did not work out for various reasons that I wouldn’t understand. Probably my fault, though. I remembered one of my engineer friends mentioning Pinecone for storing vector embeddings, so that was the next option I turned to.
To talk about my process—it was 100% vibecoding on Cursor with Claude 4. I wouldn’t know the first thing about coding such an application myself, so I had to have some fun vibing with Cursor.
While it took me maybe thousands of prompts, making me feel guilty about how much I’m probably costing Cursor, it wasn’t as scary as it seemed. I have been working on simpler projects for a few months now, and one thing I learned about vibecoding is that problem-solving skills can take you FAR. I might not be the best coder, probably among the worst, actually, but I take pride in having decent problem-solving skills. Without intervening and pointing out some obvious logic flaws Claude was making, this thing simply would not have worked. Yet, I had a somewhat functional prototype in just 2 hours!
Access Controls
The next part was trickier: Access Controls. If I’m an enterprise salesperson, should I be allowed to see another salesperson’s clients’ data? Probably not. For that reason, I decided to layer on yet another API: Oso Cloud. This meant that I would write my own authorization logic and deploy the rules on their UI; and AI is not that great at using Oso’s DSL, Polar. This is when I had to get a little bit of help from yet another friend. The next piece was adding my authorization data on Oso Cloud so that my policy knew what to apply the rules on.
Once Claude randomly generated 60 sample embeddings and built a decent-looking UI, I discovered that the authorization logic was working simply through database queries and not my authorization rules stored in Oso Cloud. This was pretty disappointing as one of my goals starting this project was to learn how to use Oso. However, it turned out to be a quick fix as I forced Cursor to default to Oso logic and data.
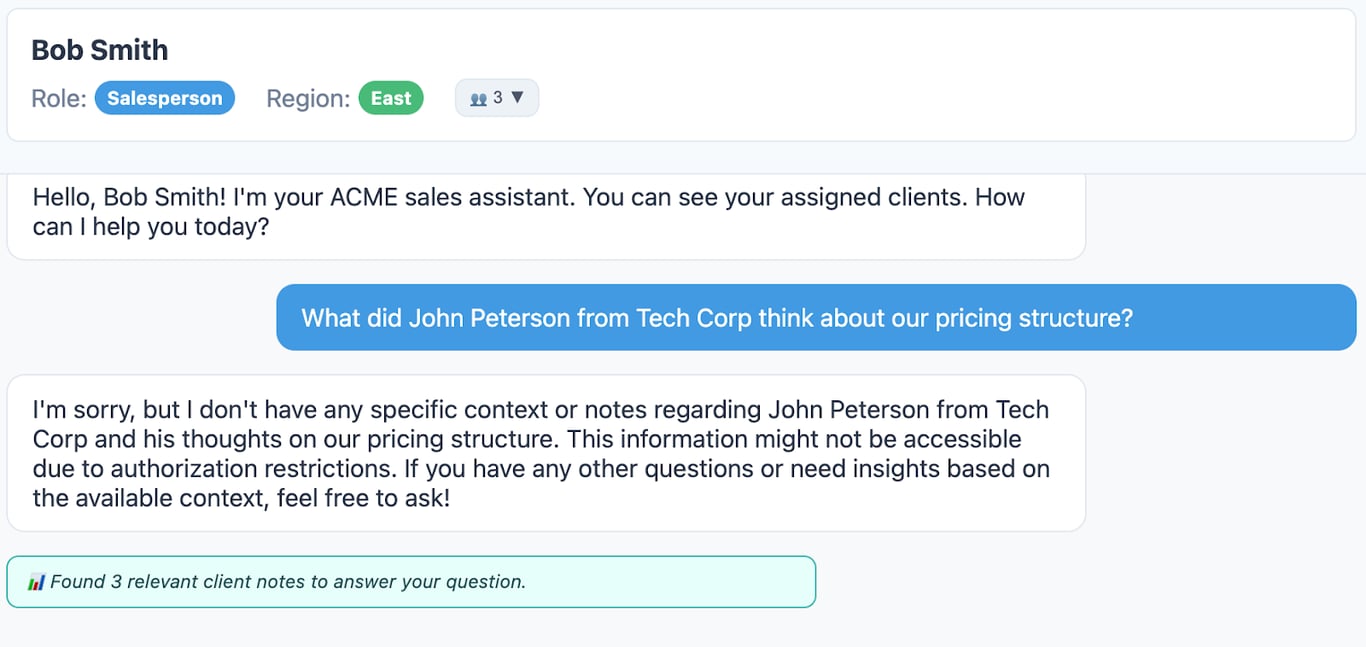
The mechanism was a bit hacky, highlighting the limitations of “vibecoding.” Each salesperson was assigned certain clients and belonged to either the East or West regions, with a sales manager for each region. For each client, there were client notes with unique IDs. Normally, I’d want to authorize at the “client note” level, but because I had no clue how to do that, I ran my authorization checks at the client level. For example, if Bob is assigned a client called Tech Industries, the authorization check for the same would return a positive result, allowing Bob to see all client notes for that particular company. In the real world, there is a chance this doesn’t work. There might be certain embeddings that you might not want your salesperson to see, even if they are assigned to that account.
Once the authorization check is completed, the next step in the app architecture was retrieving all embeddings for that client—resulting in a response that only Bob and his regional manager could see.
For instance, when Bob asks a question about one of Alice’s customers, this is the response he gets:
🔑
Note the number of embeddings found under the LLM response. This indicates that similar embeddings do exist but are not shown to Bob due to authorization checks failing as they should.
I even added some list filtering features, displaying a list of clients the user has access to on the UI, using Oso’s buildQuery function. Since AI is still not well versed in Oso, feeding it their documentation was quite helpful.
The “Security” Incident
Everything looked great to the point I was sharing my app with friends, and for the most part, my access controls were working as intended. Then, I was hit with my first major security incident. Alice could actually access embeddings associated with the client named Lisa—who was assigned to Bob. The critical nature of this breach caused a brief moment of panic. I jokingly refused to respond to “questions from the media” and continued my vibecoding session instead. Turns out, I was not referencing my Pinecone data. When I deployed my application on Railway, the automatically generated PostgreSQL database had taken over, and Client Note IDs somehow got corrupted! While it took me 2 hours to get to a prototype, resolving this issue took 2 hours on its own. Thankfully, my Pinecone embeddings were intact, linking each client to their respective notes. Forcing my “code” to default to the Pinecone database immediately addressed the security concerns of millions of users who rely on my vibecoded app for their sales operations—NOT!
What I Learned…
Overall, I’d rate this learning experience 10/10. While vibecoding doesn’t really make you a software engineer yet, it was cool to see I could actually build a sample AI/RAG application. Just that alone gives me confidence that I can continue building apps at a small scale that improve my quality of life; but no way in hell I am shipping enterprise-grade software unless I spend 10 years educating myself to become an actual engineer and not a marketing professional. That is precisely why I have enormous amounts of respect and admiration for software engineers shipping features we use daily.
A few things I learned from this vibecoding project were:
Always have the agent document application logic in a README document. The longer the conversation goes, the less the agent can remember. You can always ask for it to refer back to the README documentation to refresh its memory on how application logic was built.
Your app is as good as your prompts. When working with APIs, it is important for vibecoders to understand which endpoints and functions are available, and how to integrate them into application logic. It’s a bit of a puzzle that you need to work through sometimes.
Sometimes the agent will implement extremely faulty logic, and then fail to realize what it has done. If you can’t point these out or ask questions about potential points of failure; at best, development will take longer, and at worst, your app will not function.
Sometimes you might have to find hacky workarounds to make things work. It won’t look pretty, and performance will probably suffer; but for prototyping purposes, the most important question is around whether the app is working as intended. The agent will occasionally suggest these workarounds, but you might also need to have a strong grasp on app logic and suggest workarounds from time to time.
For those interested, this blog was super helpful for me to understand how to build this project.
When personalizing messages at scale, ensuring compliance with brand and legal guidelines can be tricky. This is how I built a simple compliance engine that plugs right into Clay!
Imagine you could just upload the job description of the position you’re applying for, and your resume; then an AI avatar interviews you live. I was able to vibecode this with minimal coding knowledge!